k8s高可用无单点故障涉及那些场景
k8s 节点添加、pod添加等增删查改无单点故障
需要元数据的存储和处理能力高可用
k8s对外的apiServer(如worker)无单点故障
worker node和其他组件访问apiServer路径高可用
k8s无单点故障技术关键点
元数据存储
通过etcd存储元数据,etcd三节点集群保证高可用
元数据处理
通过多个kube-controller和kube-scheduler节点来保证高可用
worker节点请求数据通过多ip或负载均衡来保证
节点请求通信通过多Ip或负载均衡来保证高可用,这里也有几种方式
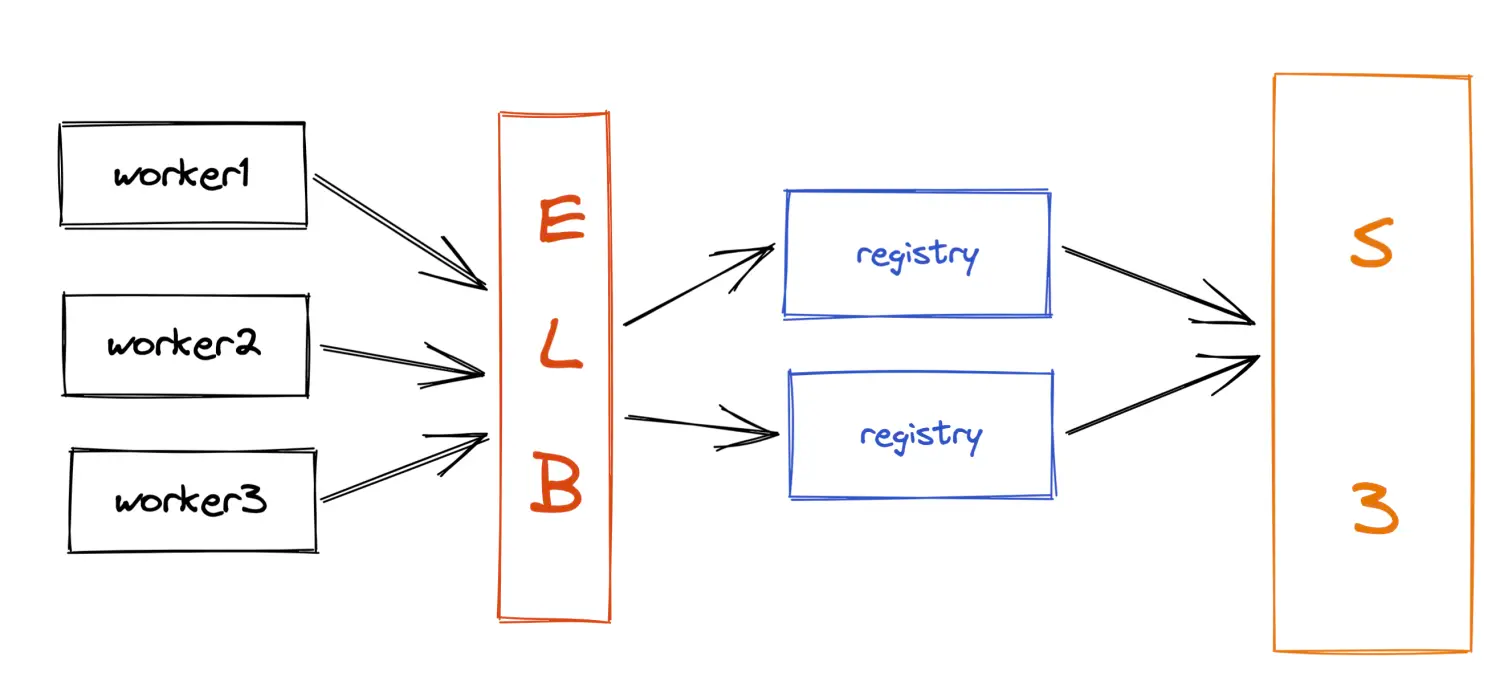
IaaS厂商可提供负载均衡的场景下
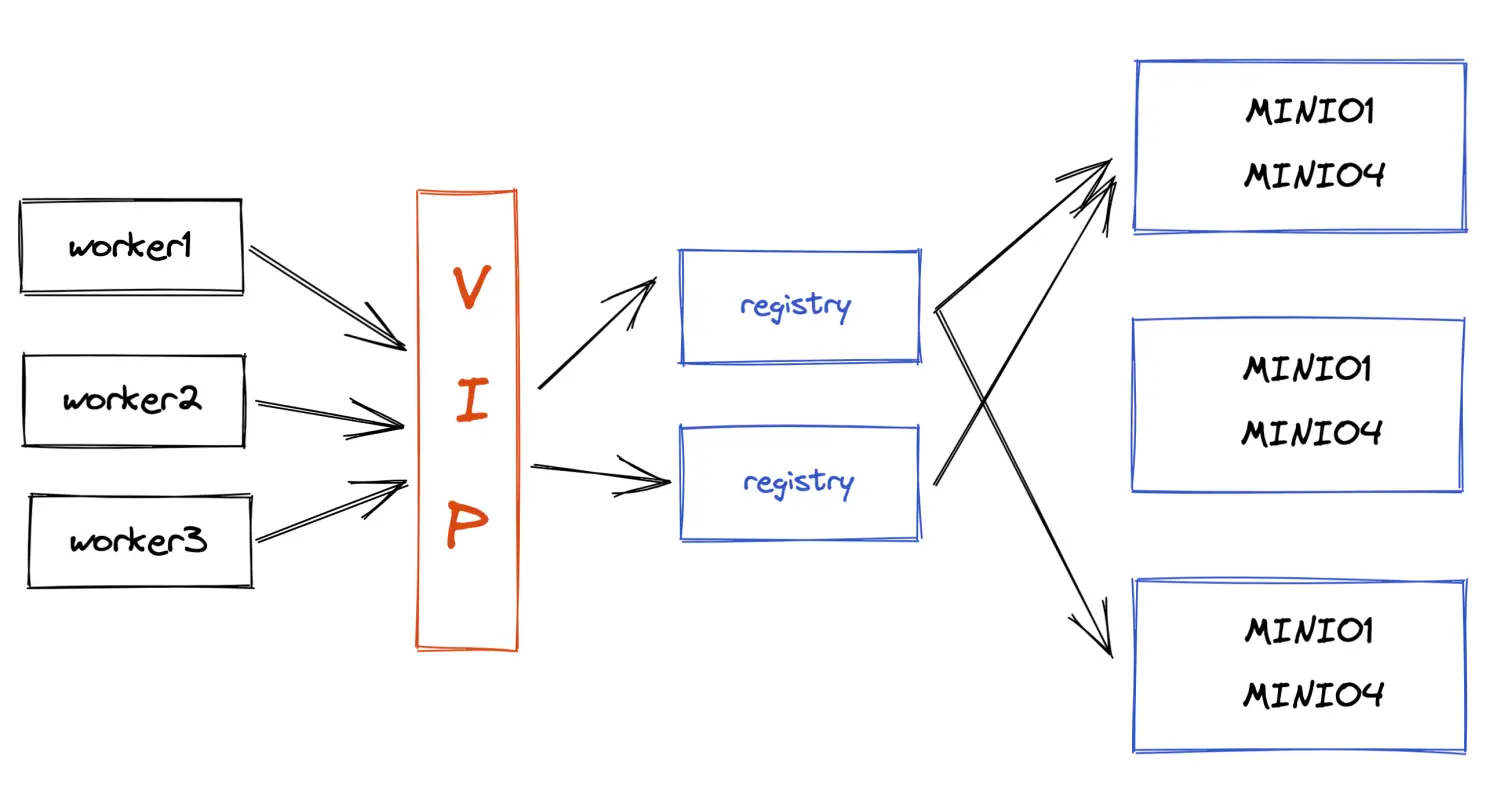
如下图所示,可将worker node的访问地址指向负载均衡的地址
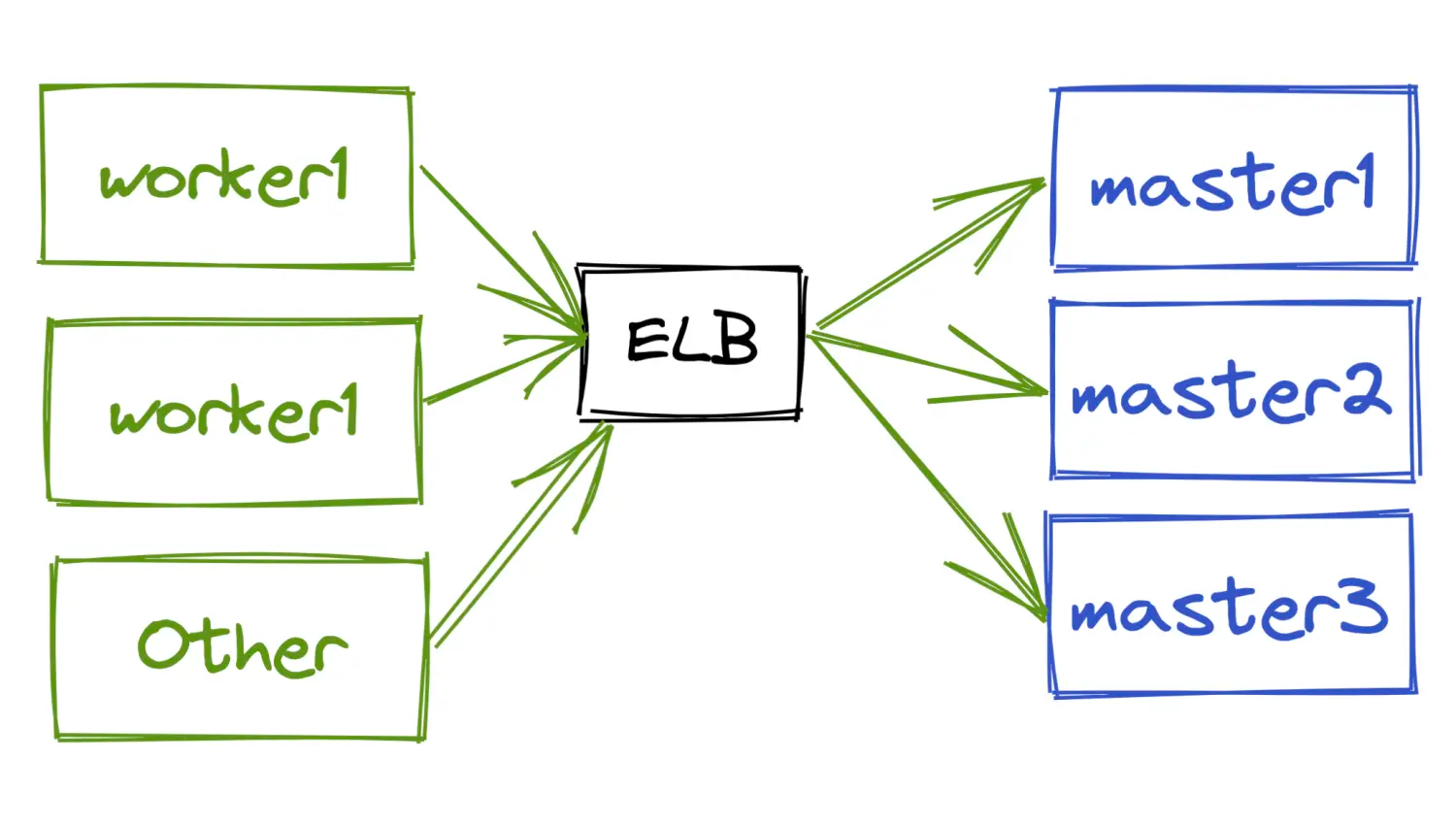
私有化部署KeepAlived
私有化部署场景常用keepAlived提供浮动IP来给worker node或其他组件访问,如下图所示
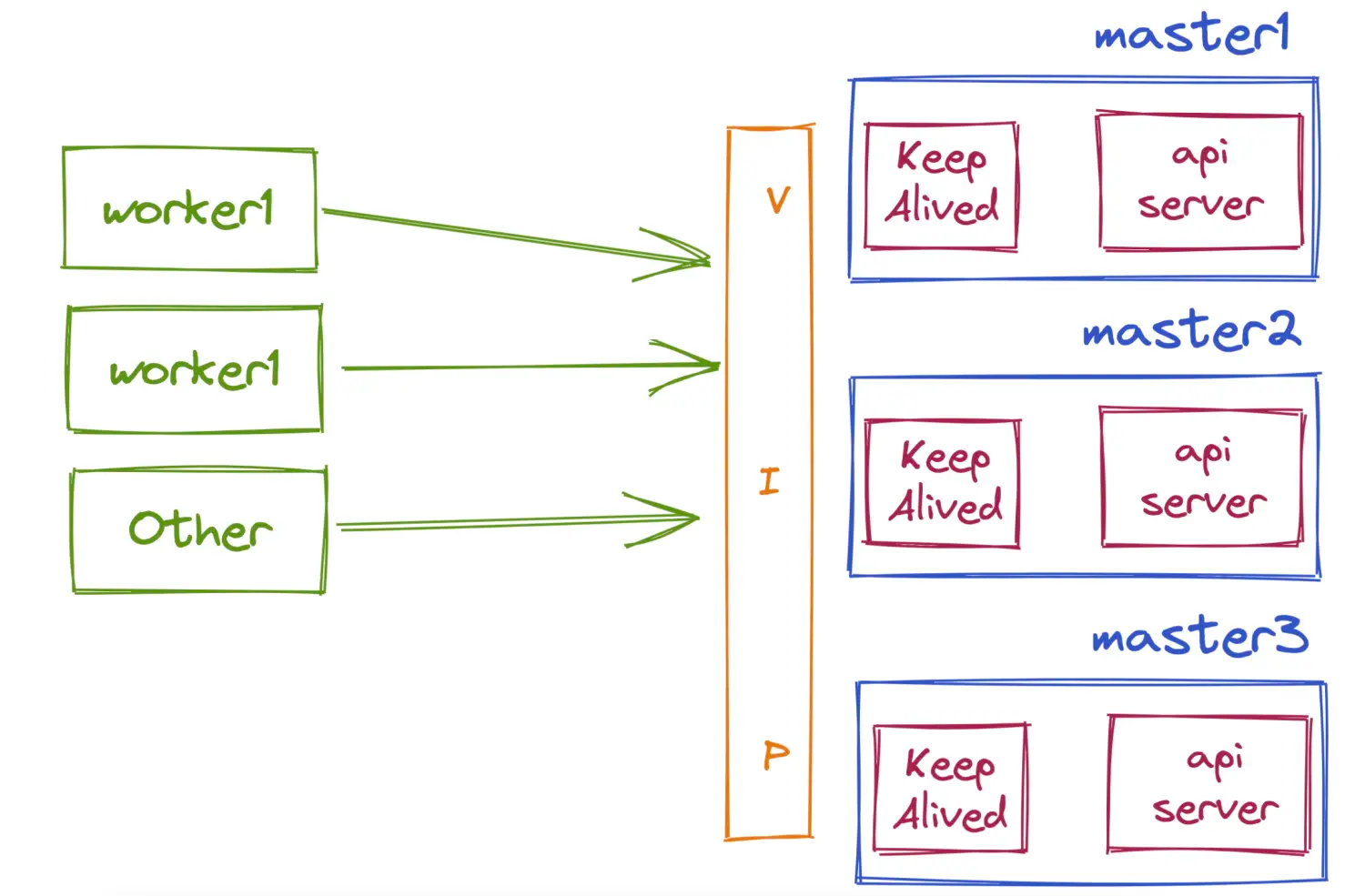
私有化部署加上负载均衡组件
如果你觉得同一时刻只有单个apiServer工作会成瓶颈,也可以使用KeepAlived加Nginx或HaProxy来对ApiServer做负载均衡
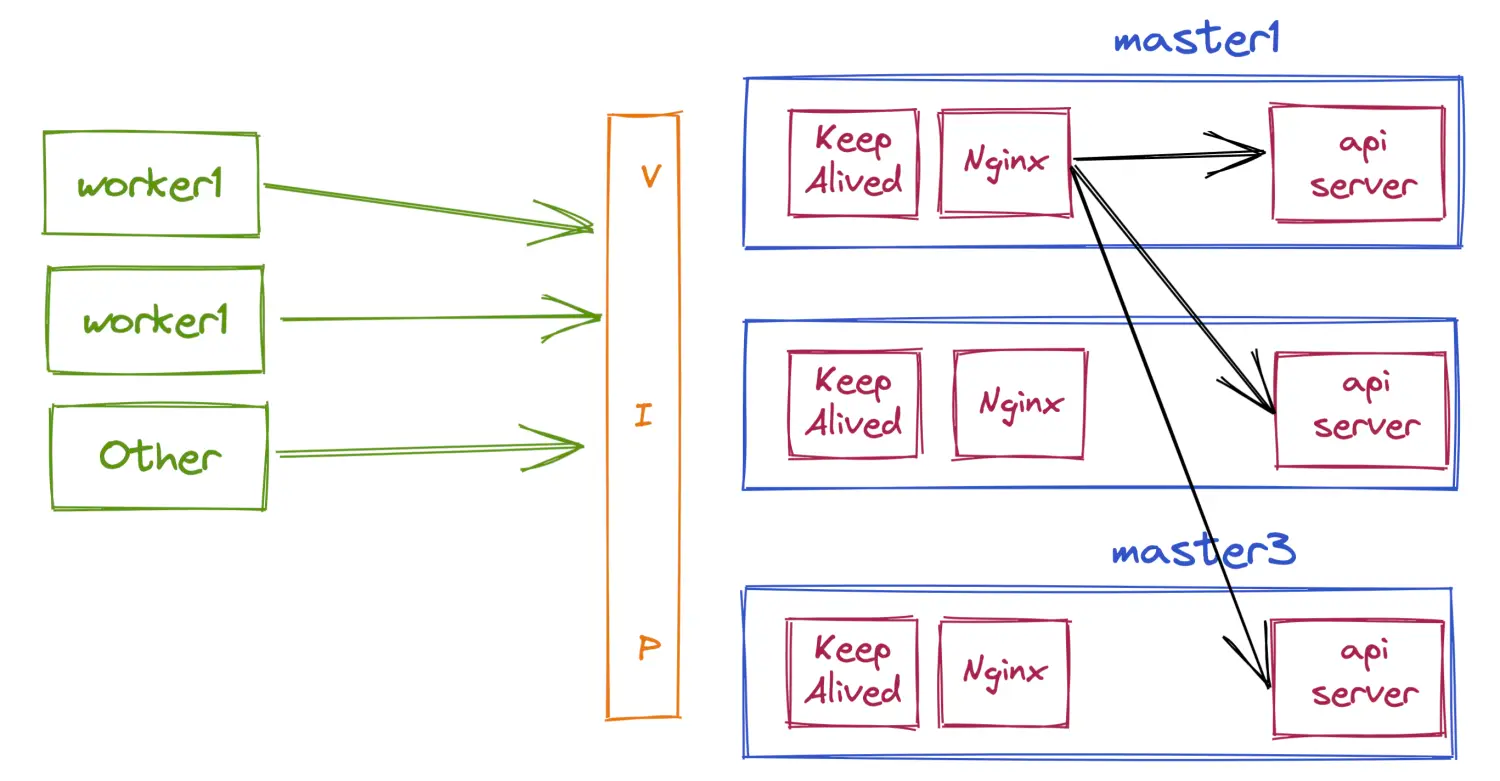
为了简化图像,只画出了master1上的Nginx向后转发的场景。
至于Nginx和KeepAlived如何部署,推荐采用容器化的部署模式,方便进行监控和运维;但是镜像不从镜像仓库拉取,而是保存在master节点上,这样虽然升级复杂一点,但是这样子kubernetes的高可用就不依赖镜像仓库了,不会和镜像仓库形成循环依赖,更不会影响镜像仓库的高可用方案,大大简化了后续的技术方案。(因为镜像仓库可能会占据较大的存储空间,可能会和master节点分离部署,这时会作为worker节点连接master节点)。